Géotraitements et analyses spatiales environnementales en masse
Que signifie Bilbo ?
Bilbo est l’accronyme de Buisness Intelligence for Land and Biodiversity Observation. C’est un projet de recherche et développement qui vise à développer des indicateurs pour l’observation de la terre.
Objectif du projet
L’observatoire de l’environnement a pour objectif de traduire l’état, les pressions, les réponses qui s’exercent sur l’environnement en Nouvelle Calédonie. Pour répondre à ces objectifs, nous collectons et analysons des données de suivi des milieux produites localement par les Collectivités, les miniers, Instituts de recherche, associations, entreprises, ainsi que des données produites mondialement comme celles obtenues par satellites d’observation de la terre:
- l’occupation des sols et l’erosion,
- les incendies,
- les indicateurs de sécheresse végétale,
- l’indicateur de pollution lumineuse
- …
La quantité d’information disponible à analyser est massive et toujours en augmentation, on parle ainsi de Big data. Pour optimiser notre productivité dans nos suivis, nous cherchons à automatiser les traitements et la publication des informations sous un format décionnel.
Problématiques principales
GeoTraitements lourds et longs
Relations spatiales
Dans un projet Bi classic (non spatial), la valeur ajouté créée provient de croissement entre les données d’un modèle structuré par des relations entre les informations : des clés de référence. Dans notre cas la relation entre les informations et AUSSI spatiale, et cette spécificité implique des calculs plus lourd que des relations par clé.
Du SIG vers un SID
L’approche que nous avons suivi jusqu’à aujourd’hui consiste à transposer le modèle d’un Système d’information Géographique en Système d’Information Décisionnelle, impliquant donc de définir quelles sont les faits et quelles sont les dimensions qui nous permettrons de répondre à la toutes de nos questions.
Les faits
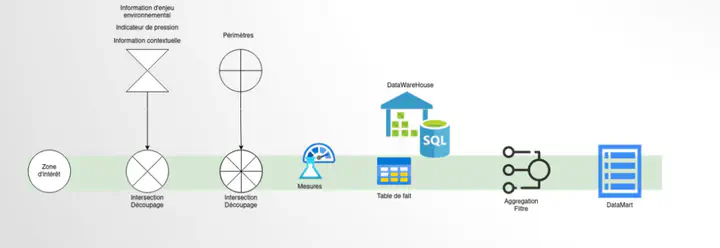
Nos premiers résultats on aboutit à la production de données constituées des résultats d’intersection géographiques entre des pressions envirommentales (les surfaces brulées par exemple), des informations de contexte (les modes d’occupation du sol) et des informations de perimètres administratifs (les limites communales). Le résultat de ces découpages constitu notre DataWareHouse, qui permet de fournir des résultats aggregés selon nos dimensions temporelles, thematiques et surtout spatiales.
Ce modèle n’est pas pleinement satisfaisant car il multiplie les croisements réaliser pour chacunes des thématiques analysés. Les bases de données sont alourdies par une redondance d’information du fait notament de la nature des données inclusives selon les échelles étudiés (une région englobe +/- plusieurs communes). D’autre par l’heterogénéités de la précisions des données que nous croisons amène à produire parfois un pailletage des objets produisant des invalidités géometriques ou des incohérences sémantiques.
Les DaTaMart (DTM)
Ce sont les tables issu d´aggregation des fais selon les dimensions choisies. Ces tables sont ensuite utilisées pour produire des rapports, des cartes, des analyses statistiques. Ces tables sont produites par des scripts SQL, et sont stockées dans une base de données relationnelle. Les scripts SQL sont redondants et donc l’usage du framework DBT apporte une amelioration en terme de maintenabilité et de lisibilité des scripts.
Vers une approche plus performante
Les effets de bord de notre approche actuelle m’ont amené à réfléchir à une approche plus performante, plus robuste et plus flexible. L’utilisation d’un index spatial léger et qui optimise les calculs de relations spatiales. L´article suivant présente cette approche :
Indexer toute l’information environnementale sur une grille vectorielle H3